Organizing the Public Data about your Research Organization
If you’ve ever read a scientific paper, you know that the information that makes it into the author affiliations is a mess. I’m a big fan of Manubot and fully support its mission to upend the modern scientific publishing model. Like how they use structured ORCID identifiers for identifying authors in manuscript metadata, they are also working towards using ROR identifiers for organizations. There are still a few growing pains for ROR, so I chimed in on a discussion on GitHub about how Wikidata might be a potential solution for organizing and retrieving information about reserach organizations. I said I’d describe my idea more in detail, so here I go!
Step 1: Wikidata
Wikidata is an open, community-curated platform of knowledge. It stores entities, their relations to other entities, their relations to scalar values, and added context for each relationship. Typically, relationships have a subject, relation, and object and can be read like a simple sentence in the english language.
There are lots of working groups that maintain its ontology (i.e., the rules for how curation should be done) around certain domains, such representing organization structures. This means there are lots of tools already built in to Wikidata for potential curators like you and me to create rich pages for their organizations.
One of the curation rules shared across all domains in Wikidata is that each entity should have a “type”. This means on the page for Albert Einstein, there is a relationship stating he is an instance of a human. The “instance of” item on Wikidata is a special kind called a “property” and is one of the places where the ontology lives - there are specific rules for each property on how it should be used in a relationship, like what’s allowed to be the subject and what’s allowed to be the object. For”instance of”, there are no rules about the subject. However, the object of the relationship where “instance of” is the property should be a “class” of thing. It wouldn’t make sense for the type of another entity to be an instance of “Albert Einstein”.
Ontology for Organizations
When making a Wikidata page for an organization, it should have a type of either organization or one of its subclasses representing various kinds of organizations, parts of organizations, or combinations of subclasses and parts. Some examples are:
- university research group like the Laboratory of Systems Pharmacology
- research institute like the Fraunhofer SCAI
- department like Fraunhofer SCAI Department of Bioinformatics
- university like Northeastern University
- faculty like the Maastricht Faculty of Health, Medicine and Life Sciences
- academic department like Maastricht University Department of Bioinformatics (BiGCaT)
- business like Pfizer
Typically, organizations have certain pieces of information associated with them using the following properties:
- short name - is there a short version of your organization’s name? BiGCaT is again a good example.
- country - in which country is your organization based? Wikidata already has items for countries, so the autocomplete will help you fill out this very easily.
- official website - what is the URL of the homepage for your organization?
- part of and has part - what are the parent organization(s) and child organizations? If your item is a department, it is likely “part of” a school, faculty, college, university, or research institution. It’s best to be as specific as possible. If you are describing a department that is part of a faculty in a university (see the BiGCaT example above), it doesn’t make sense to be redundant and also write that it is a part of the University.
- field of work - what topics do your organization work on / research? This can be things like cancer, machine learning, etc.
Leadership and organizer links:
- chairperson - who is the leader of the organization? This person should themselves have a Wikidata page. For a department, this is equivalent to the department chair/head.
- chief executive officer - who is the CEO of a business?
- founded by - who founded a business?
- director / manager - who is the PI of the lab?
External Account Links:
Tutorial
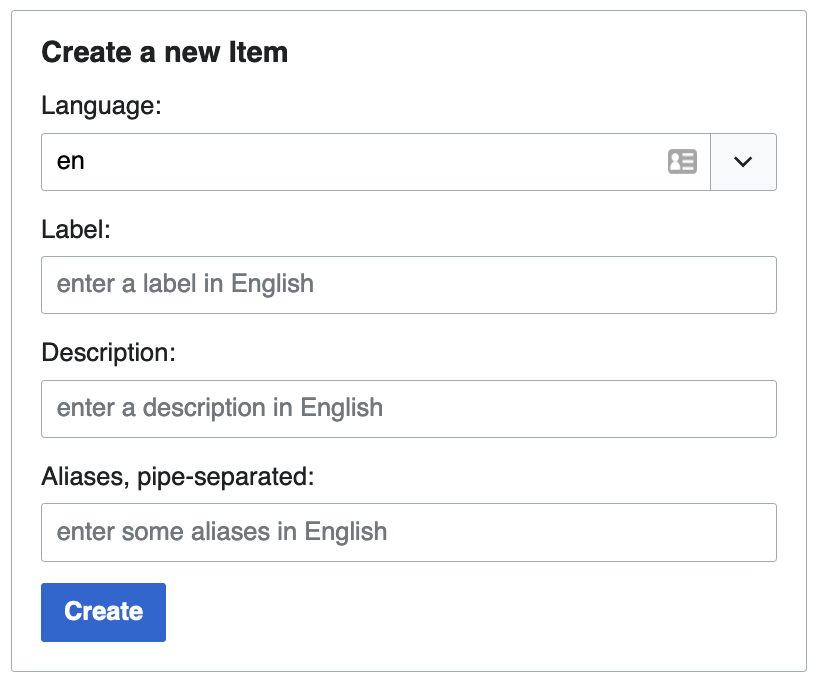
- Create a new item. You don’t need to have a Wikidata account or be logged in, but there are lots of benefits, so that’s highly suggested through this portal.
- Input the name for the item. If you’re making a page for the Northeastern
Department of Chemistry, it makes most sense to include the name of the
parent organization inside the label for the item. There are some instances
where this isn’t the case, such as the example above of the Maastricht
Faculty of Health, Medicine and Life Sciences, but this could cause
confusion. The rest of the form is pretty obvious, but if you aren’t sure
what to entry for the description, writing what kind of thing it is might be
best. For the Northeastern Department of Chemistry, one might write “academic
department”
- You’ll see a mostly blank page. Start by clicking the “+ add statement” link
in the middle to bring up the following box. On the left where “Property” is
greyed out, you can type the name of the relationship and click the right
suggestion from the dropdown
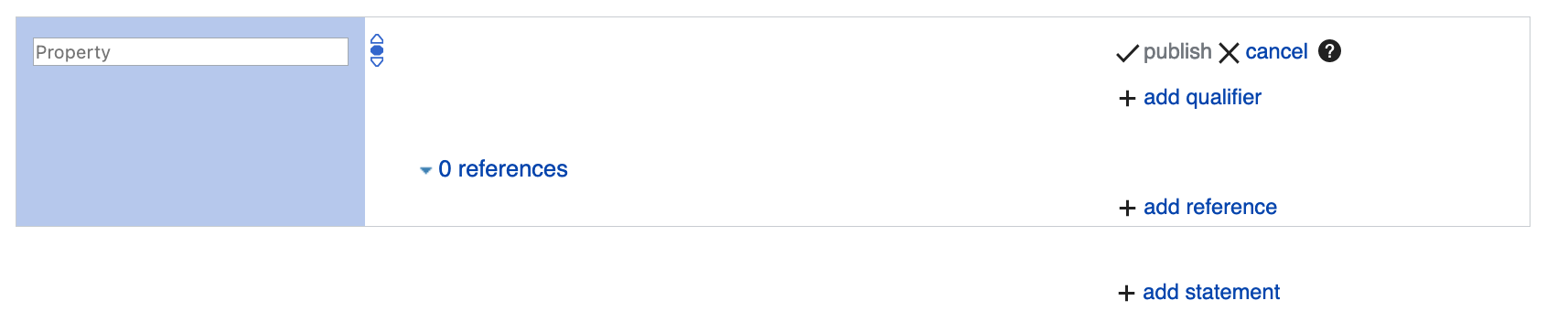
- In the middle, you can type the object of the relationship. If the property
accepts another Wikidata item, it will show an autocomplete field. If the
property accepts a scalar (like an identifier), then no dropdown will pop up.

- After checking what you’ve typed is correct, click publish! Don’t worry, all
items can be edited/updated later.

- Repeat for all information you know about the organization. It’s a bit high-minded, but you can also follow the links for the properties mentioned above to see the rules they define for how they should be used. The cool thing about ontologies is that properties can actually be the subject of relationships that describe how they work using “meta-properties” 🤯.
If you’ve got any suggestions for improving this tutorial, feel free to get in touch with me (contact information at the bottom of this post) or make a PR to this page directly on GitHub!
Step 2: Research Organization Registry
The Research Organization Registry (ROR) is an organization dedicated to assigning unique identifiers to all research organizations. Definitely check out their homepage, I couldn’t write it any better than they did. They can accomplish the same goal that you can on Wikidata, but there’s a clear advantage towards having nomenclature authorities that manually curate and maintain data.
Their curation page has a link to their request form where you can send information about your organization to them. Even better, they accept Wikidata identifiers, so you don’t have to type everything all over again! I personally filled out the form and had some very nice email exchanges later with their team, so I hope you have a nice experience too. Eventually, they will assign your organization a ROR identifier as well as curate relationships between your organization and others.
Finally, the whole loop that started with Wikidata can be closed by copying your newly minted ROR identifier back to your organization’s Wikidata item. Wikidata has a property ROR ID whose object is the scalar identifier from ROR!
Step 3: Optional but Cool Things
Wikidata, ROR, and GRID (below) are by far the best solutions for storing scholarly metadata because of their licensing and API accessibility. Ringgold and ISNI are not good options for building a reusable infrastructure since they are both closed and paid systems, but they are still relevant (until the revolution) for some aspects of modern scientific publication.
Global Research Identifier Database
The Global Research Identifier Database (GRID) is a parallel effort that imports data from ROR on a quarterly (every three months) basis. It assigns an additional GRID identifier to an organization that is already in ROR. GRID is released about every three months via FigShare under the Creative Commons Public Domain 1.0 International license, which means anyone can use it any way they want.
Like with ROR, GRID has a Wikidata property GRID ID that links a Wikidata item to the scalar GRID identifier.
August 10, 2021 update: GRID is shutting down and getting consumed by ROR (ref).
Ringgold and ISNI
Many publishers use the Ringgold system for organization resolution (such as Manuscript Central). For a group interested in scholarly publishing (which could either be an academic or commercial organization), you can simultaneously apply for a Ringgold and ISNI by emailing isni@ringgold.com (copied from their FAQ).
These can be linked to a Wikidata item with the Ringgold ID and ISNI properties.
Scholia
Once your Wikidata page is full of information, you can use Scholia to visualize all the information attached to your organization through Wikidata. For example, see the University of Cambridge. To get the most of this, you should annotate for each member of your organization that they are affiliated, have been educated at, or have been employed at your organization, whether it’s current or past - Wikidata has additional metadata for a relationship for representing the time period during which it was true.
Scholia shows off how easy it is to build a system on top of the data in Wikidata and the (free!) SPARQL infrastructure they provide for accessing the data however you want. This is the original reason for me bringing up Wikidata in the Manubot issue tracker. It would be totally reasonable to hit their SPARQL endpoint with one query per Manubot build and continue being good open source citizens.
This blog post might have gone off on a couple tangents besides what was relevant for Manubot, but because I did all of these things to set up the internet presence of my previous employer, it could serve as a good guide for any new organizations to get up to speed.
See also the newer post on organizing all of the public data about a researcher, like you!